Asymptotic Analysis
So far we built up intuition about what it means to perform complexity analysis and learned how to model the number relevant operations a program performs using mathematical functions. However, as mentioned previously, computers are fast enough that on small inputs, virtually any set of algorithms that solve the same problem will perform identically. Rather than worry about small inputs, we would like to understand how our program behavior scales when it is given larger inputs. The study of this scaling behavior is called the asymptotic analysis of algorithms, and the main tool we use to express this behavior is Big-O notation. In this section we'll study this mathematical formalism and tie it back to the informal reasoning we will need to perform on a day-to-day basis.
Growth of Functions
We model the complexity of computer programs using mathematical functions. And we can categorize the different mathematical functions in terms of how their outputs grow relative to their inputs.
-
Constant Functions are those functions that do not depend on their input. For example is a constant function that evaluates to , irrespective of its input. A function that swaps two indices of an array always writes twice to an array no matter what the length of the array is or what indices are given.
public static void swap(int[] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } -
Linear Functions take the form where and are constants. They correspond to lines. For example, walking an array, e.g., to find a given element, takes linear time.
public static boolean contains(int [] arr, int k) { for (int i = 0; i < arr.length; i++) { if (arr[i] == k) { return true; } } return false; } -
Quadratic Functions take the form where , , and are constants. They correspond to curves. Functions with quadratic complexity arise, for example, when we must perform an operation involving all possible pairs of a collection of objects. For example, consider a function that computes the Cartesian product, i.e., set of all possible pairs, of an array of elements.
class Point { public int x; public int y; public Point(int x, int y) { this.x = x; this.y = y; } } public static Point[] cartesianProduct(int[] arr) { Point[] result = new Point[arr.length * arr.length]; for (int i = 0; i < arr.length; i++) { for (int j = 0; j < arr.length; j++) { result[arr.length * i + j] = new Point(arr[i], arr[j]); } } return result; }If there are objects, then there are operations that must be performed.
-
Cubic Functions take the form where , , , and . They correspond to curves with an inflection point and have a slope greater than a quadratic function. Functions with cubic complexity arise, for example, when we must perform an operation involving all possible triples of a collection of objects. You can imagine generalizing the Cartesian product code above to produce all three-dimensional points drawn from an input array. Like the quadratic case, if there are objects, then there are operations to be performed.
-
Polynomial Functions generalizes all the previous functions discussed so far! A polynomial has the form where each and are constants. In practice, we'll distinguish between constant time (), linear time (), and polynomial time () functions.
-
Exponential Functions take the form where and are constants. They correspond to curves but with a steeper slope than any polynomial function. Exponential functions arise, for example, when we have to consider all possible subsets of a collection of objects. For a collection of objects, there are possible such subsets.
A common "exponential" we'll encounter in computer programming is the factorial function, . corresponds to the number of possible orderings or permutations of elements. By Stiring's approximation:
This term's growth is dominated by the term which is exponential.
-
Logarithmic Functions take the form . When using we usually assume the base of the logarithm is 10 (so that ). However, in computer science, we usually assume is base 2. It turns out the base of the logarithm is usually irrelevant for our purposes of asymptotic analysis because via the change-of-base rule:
Logarithms of different bases only differ by a constant amount (the term in the denominator of the fraction).
Logarithmic functions arise when we are able to divide a problem into sub-problems whose size is reduced by some factor, e.g., by half. When these problems are smaller versions the original problem, we call them "divide-and-conquer" problems and frequently use recursive design to solve them. The canonical logarithmic function is binary search where, instead of removing one element from consideration on every iteration, we remove half of the elements of the (sub-)array we are examining.
-
Linearithmic Functions are "linear-like" functions multiplied by some logarithmic factor, i.e., have the form . Linearithmic functions arise when a divide-and-conquer sub-problems requires a linear amount of work. For example, the most efficient general-purpose sorting algorithms have this runtime.
Big-O Notation
When we perform complexity analysis, we would like to classify the growth behavior of our program according to one of the classes of functions listed above. We use Big-O notation to capture this fact. When we write for some function , we refer to the set of functions that are all in the same growth class as . For example, where , refers to the class of linear functions such as:
If we, therefore, think of as a set of functions, we can write to mean that function belongs to the same class of functions that belongs to (i.e., the class denoted by . The functions above are all in the same complexity class so , , , , etc.
We can categorize the complexity of our functions by using big-O notation in tandem with the mathematical models we build to count the functions' relevant operations. For example:
- The number of array operations performed by the
swapmethod is where is the size of the input array. We can say that , declaring that the runtime of \ji{swap} is in the constant complexity class. - The number of array operations performed by the
summethod is where is the size of the input array. We can say that , declaring that the runtime of \ji{sum} is in the linear complexity class.
Note that when describing the complexity class in practice, we:
- Rather than saying where which is overly verbose, we simply inline the body of the complexity class function with the notation. For example, we write instead of where .
- Use the simplest function in that class, e.g., instead of or . While using more complicated classes is technically accurate, such usage loses sight of the fact that we are referring to the class of functions that are linear rather than a particular such function. In particular, with the constant complexity class we always write since it relates together all constant functions together.
The Formal Definition of Big-O
So far, we've developed an informal idea of Big-O—a classification of the growth rate of mathematical functions. Now let's unveil the specifics. The formal definition of Big-O is:
What does this mean? First of all, for some function of interest , we say that , pronounced " is oh-of-" or " is order ". This is true whenever there exists () two constants and such that for all () where the following inequality holds: . That is dominates by some constant factor after some starting input .
captures the idea that is bounded above by . To prove this fact about a particular and , we must provide the two integers demanded by the existential:
- , a constant factor that is multiplied by and
- , the minimum input size to consider.
Such that for all input sizes greater than or equal to , is less than or equal to . That is, from on, is also smaller (or equal) to within a constant.
For example, let's show that where and . First let's examine a graph of the two functions:
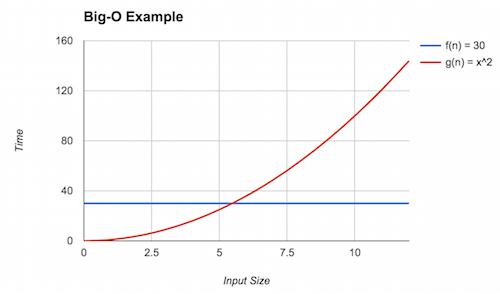
We can see that eventually (the red line) dominates (the blue line), but what is that point? This is the point where . Solving for yields . Thus, we can claim that (rounding up to be safe) and . Here, we see the inequality holds because . With this, we can conclude that .
Big-O provides an upper bound on the asymptotic complexity of a function. For example, in the above example as well. To see this, note that for , . However, this is a weak upper bound because many other classes of functions are "smaller" than factorial, for example, polynomials and linear functions.
We always want to provide the tightest bound possible. Because we are not analyzing pure mathematical functions but, instead, computer programs with arbitrary behavior, it will sometimes be impractical, infeasible, or impossible to give a precise model and, thus, tight bound. We will therefore resort to a less tight bound in these situations. For example, you may suspect that the program has quadratic complexity () but have difficulty proving it, so instead, you may claim a cubic bound () instead which may be easier to show.
A Note on Notation
In our presentation of Big-O, we have been consistent in interpreting as a set of functions in the same complexity class as . in this situation serves as the representative function for that complexity class and some other function \ We then say some other function is also in this class with set inclusion () notation.
While this notation is consistent with the set-theoretic interpretation of Big-O that we present, it is not the traditional way that we write Big-O! Instead, Big-O traditionally written with equality:
The traditional equality notation here obscures the idea that really denotes a set! We'll continue to use set notation throughout this text. However, be aware that in other presentation of Big-O, you'll see equality notation which means the same thing!
Additional Asymptotic Bounds
Big-O notation gives us a way of describing the behavior of a function as its input grows. In mathematics, we formally define this as taking the limit of the function (typically to infinity). Thus, our techniques above are an example of asymptotic analysis where we analyze the limiting behavior of mathematical functions.
The definition of Big-O described previously has many parts to it. By changing this definition we obtain other useful notations for describing the asymptotic behavior of functions. For example, consider flipping the inequality relating and . We obtain the following definition:
When it is that dominates , we write (pronounced " is big-omega of "). Intuitively, this definition states that is a lower bound of . In the context of computational complexity, this means that the algorithm corresponding to performs no better than the algorithm corresponding to . For example, it is known that any comparison-based sorting algorithm is , i.e., no such algorithm can perform better than .
If serves both as an upper- and lower-bound for , we write (pronounced " is big-theta of ").
Here, describes exactly the family of functions in which resides. Often we would like to characterize our models with big-theta bounds. However, it is frequently onerous, difficult, or both to prove that is a lower bound, let alone an upper bound, so we frequently stick with big-O bounds instead of big-theta.
Finally, note in the statements above that we posit that there exists a constant that inflates appropriately. This implies that there may exist some constants where the desired inequality—less than for big-O and greater than for big-omega—does not hold. We can make a stronger claim by asserting that the inequality holds for all constants rather than at least one:
These "little" versions of big-O and big-omega ("little-o" and "little-omega", respectively) make a strictly stronger claim than their big counterparts by asserting that the desired inequality holds, irrespective of the chosen constant. In practice, this means that and are in strictly different families of functions.
Recall that you gave best, worst, and average case mathematical models of the max method in a previous reading:
public static int max(int[] arr) {
if (arr.length == 0) {
throw new IllegalArgumentException(); // ignore this case
} else {
int ret = arr[0];
for (int i = 1; i < arr.length; i++) {
if (ret < arr[i]) {
ret = arr[i];
}
}
return ret;
}
}
Give a big-O bound, the tightest possible bound you can, for each of those models.